며칠 전에 면접을 봤는데, 거기서 커넥션 풀에 대한 질문이 나왔다.
그런데 대답을 잘 못해서 아쉽기도 했고, 면접 직후 찾아보니 HikariCP에 대한 이야기도 나오길래
어? 맨날 springboot 켜면 나오는 hikari가 커넥션 풀을 관리해주는 거였어?
하고 관심을 가지게 됐다. 그래서 이번 글은 커넥션 풀과 hikariCP에 대한 소개.
DB 커넥션 풀
커넥션 풀은 데이터베이스와 연결된 커넥션을 미리 만들어 풀에서 관리하고, 필요시 이를 사용하고 반환하는 기법이다. 이는 데이터베이스 연결 수행 및 읽기/쓰기 작업에 관련된 오버헤드를 줄이는 것이 주 목적인 데이터 엑세스 패턴이다.
또한 이는, 가장 기본적인 수준의 DB 연결 캐시라고 할 수 있다.
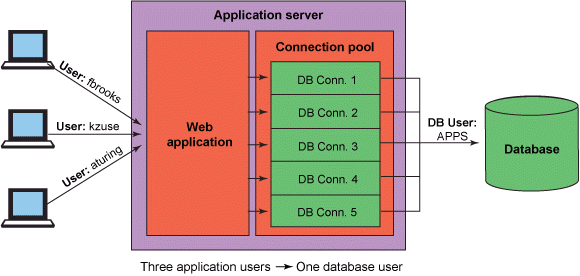
이렇게만 들으면 감이 안올텐데, 일단 예시를 먼저 보자.
커넥션 풀이 없다면
일반적인 데이터베이스의 연결 단계를 생각해 보자.
- 데이터베이스 드라이버를 사용해 데이터베이스 연결 열기
- 데이터 읽기/쓰기를 위한 TCP 소켓 열기
- 소켓을 통한 데이터 읽기/쓰기
- 연결 닫기
- 소켓 닫기
할게 엄청 많다...그리고 저 과정은, 모두 엄청난 비용을 가지는 작업이다!
만약 트랜잭션을 한번 열 때마다, 혹은 요청이 한번 들어올 때마다 저 동작을 수행한다면?
실제 연산이나 쿼리 시간보다 연결 시간이 더 걸려서 최적화가 어려워질 것이다.
그런데, 여기서 하나의 아이디어를 떠올릴 수 있다.
만약 저렇게 비용이 많이 드는 연결 작업을, 프로젝트를 시작할 때 미리 해두면 어떨까?
그리고, 미리 만들어 둔 100개(혹은 그 이상의)의 풀을 필요할 때 대여해서 쓰고,
다 쓰면 다시 반납한다면? 위의 단점들이 상쇄되는 것을 볼 수 있다.
DB와 통신할 때 비용이 거의 무의미한 수준으로 축소된다는 강점이 있기 때문이다.
커넥션 풀의 개수는 어느 정도가 좋을까?
면접때 받았던 질문이다. 커넥션 풀이 무제한으로 많으면 무조건 좋은 거 아니냐? 듣고보니 일리가 있었다.
내가 했던 답변은 "그러면 DB가 못버티지 않을까요?ㅎㅎ" 였는데, 영 아쉬워서 관련 내용을 찾아봤다.
그랬더니, 다행히 훌륭한 레퍼런스가 많아 적절한 개수에 대해 고민해 볼 수 있었다.
MySQL의 Connection Pool에 대한 공식 레퍼런스에서는, 의외로 600여명의 유저에 대응하는 데에 15~20개의 커넥션 풀만으로도 충분하다고 언급하고 있다. 여기에서는 최대 연결 수를 무제한으로 설정한 뒤 부하 테스트를 진행하면서 최적화된 값을 찾아나가는 것을 추천하고 있다.
우아한형제들 테크블로그에서는 아래의 공식을 추천하고 있다.

- Tn = 전체 Thread의 개수
- Cm = 하나의 Task에서 동시에 필요한 Connection 수
해당 게시물은 HikariCP의 데드락 이슈와도 연관된 글이라 이 부분이 강조되었다.
해당 공식은 HikariCP wiki에서 Dead lock을 피할 수 있다고 언급된 공식이라고 한다.
(DBCP의 데드락에 대해서는 같은 블로그의 이 글부터 먼저 읽어보시길 추천드린다.)
또한 위의 공식에서도 유추할 수 있는 것이지만, Thread의 개수는 pool size를 결정하는 데 중요한 요인이다.
Thread Pool의 크기보다 Connection Pool의 개수가 크다면, 남는 커넥션 풀이 생겨서 메모리만 차지하게 되기 때문이다. 또한 DB와 WAS의 Context Switching 역시 한계가 있으므로, 어느 쪽이든 적절한 병렬 연산의 수행 대신 Blocking이 발생할 수 있다는 문제점이 있다.
위의 내용은 이 블로그를 참고해 작성했다. 너무 잘 쓴 글이라 큰 도움이 되었다.
HikariCP
커넥션 풀에 대해 자세히 고민해봤으니, 이제 HikariCP에 대해서 소개하려고 한다.
HikariCP는 2012년 처음 개발되었으며, 130kb의 가벼운 용량과 빠른 속도를 가지는 JDBC의 커넥션 풀 프레임워크이다.
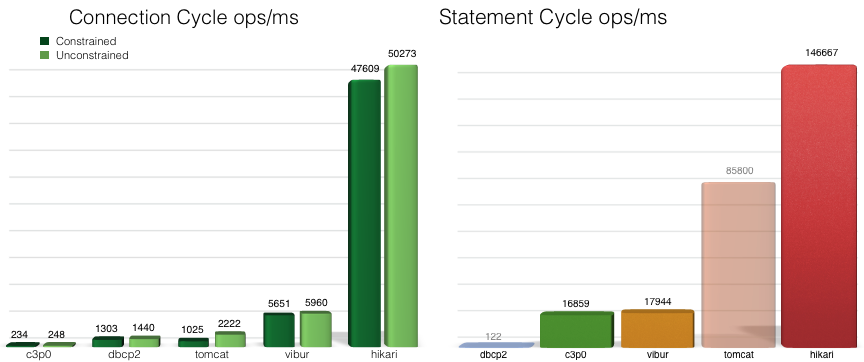
벤치마크에서 알 수 있듯, 엄청난 최적화 속도를 보여주고 있다.
이러한 성능에 힘입어, SpringBoot는 2.0 버전부터 기존에 커넥션 풀 관리를 위해 사용하던 Tomcat을 HikariCP로 교체했다. 그래서 spring-boot-starter-data-jpa나 spring-boot-starter-jdbc를 의존할 경우, 자동으로 HikariCP가 포함된다. (링크)
사실 그러한 이유로, SpringBoot를 잘 사용중이라면 HikariCP가 커넥션 풀을 관리해주는 것을 모르는 분들도 있었을 것이다.(어제까지의 나 포함...)
HikariCP의 옵션
application.yml에서 HikariCP의 속성값을 조정해줄 수 있다.
spring:
datasource:
hikari:
connectionTimeout: 30000
maxinumPoolSize: 10
(...)위에서 보듯, spring.datasource.hikari.~~로 속성을 넣어줄 수 있다.
아래는 설정할 수 있는 속성의 목록이다. 자세한 설명은 공식 github의 README에서 참조하길 바란다.
autoCommit
- default: true
connectionTimeout
- default: 30,000(30s)
idleTimeout
- default: 600,000(10min)
maxLifetime
- default: 1,800,000(30min)
connectionTestQuery
- default: none
connectionInitSql
- default: none
validationTimeout
- default: 5,000
maximumPoolSize
- default: 10
poolName
- default: auto-generated
allowPoolSuspension
- default: false
readOnly
- default: false
transactionIsolation
- default: driver default
leakDetectionThreshold
- default: 0
HikariCP의 보다 자세한 사용법에 대해서는 해당 링크를 참조하길 바란다.
추후 좀 더 코드를 분석해서 게시글을 추가 작성해보려고 한다.
마치며
원래 글을 쓴 목적은 이뤘지만, 참고한 글들에 비해 너무 빈약한 결과물이 나온 것 같다.
특히 HikariCP에 대해서는 자세히 분석한 글이 많아 재밌었는데,
나도 조만간 코드 좀 뒤져보며 공부해볼까 욕심이 난다.
잘못된 내용이 있다면 댓글 부탁드립니다. 감사합니다.
참고
'프로그래밍 > JPA, Database' 카테고리의 다른 글
| 관계형 데이터베이스의 데이터 무결성 (0) | 2021.10.29 |
|---|---|
| [JPA] 비관적 락과 낙관적 락, 트랜잭션의 격리 수준 (1) | 2021.10.15 |
| H2로 SpringBoot 테스트 도중 SQL이 실행되지 않는 경우 대응법 (0) | 2021.10.08 |
| [JPA] findAll, findAllBy, findAllByIn AOP로 성능 테스트해보기 (6) | 2021.09.02 |
| [JPA] Bean Validation과 Hibernate apply-to-ddl (1) | 2021.02.22 |




댓글